
What (exactly) IS Google Knowledge Graph?
Google Knowledge Graph is technically a knowledge base containing information acquired from several sources and their relationships in order to enhance the search results. This concept was introduced in the year 2012 as a way of providing more relevant, accurate, and helpful information based on what users search on the Web through the search engines. The knowledge graph presents the information to users in several ways, most notably via an infobox or knowledge panel usually placed next to the results.
The knowledge panel presents a wide variety of information concerning a subject or entity. For example, when a user types the name of a famous musician, the knowledge panel displays such details as the musician’s full name, images, list of songs, their recent tracks, upcoming events, partners, and other details. This is made possible by the knowledge graph as it creates a database by using the data available about the entity to create meaningful relations.
The user experience is improved greatly by the knowledge graphs since one is availed with an extensive range of information on a concept thus eliminating the need to keep on searching for a specific topic. This results in a reduced number of clicks, and it reduces the amount of time required to locate matching content.
The knowledge base is created by forming relationships between various entities. Entities in this case refer to concepts or things that are distinguishable including colour, people, location, a feeling, and organizations among others. Machine learning and other algorithms are deployed in the knowledge graphs to provide the most relevant and useful information to searchers. Interlinking data from millions of sources and utilizing machine learning concepts enables the knowledge graphs to come up with a knowledge base that has helpful and accurate information about the entities. When searching for some content via the Web, the graphs utilize semantic search methods to return the most relevant feedback. The knowledge graphs are designed in such a way that they can analyze the relationship between keywords and phrases to better understand what the user is interested in, or to understand the search’s context that return matching results.
Edges are used to connect the various entities and provide a description of the nature of the relationship between these entities. Through the knowledge graph, Google is able to present searchers with more information that is relevant to the specific search, and also increases the traffic for search engine optimization (SEO). Google’s knowledge graph helps in enhancing voice searches by identifying the entities in queries made using natural language. A business can benefit from knowledge graphs because it normally provides detailed information about the business after a search. Users find information about future events planned by a business that is beneficial to the business.
Some Knowledge Graph Detail
For example, consider the following sentence:
“Queen is a rock band”
An example of a “Semantic triple”
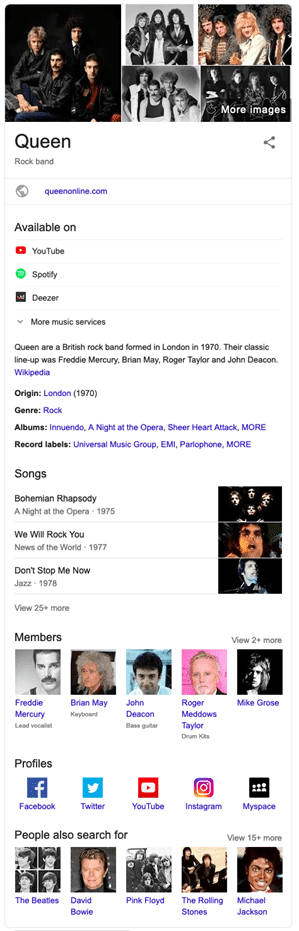
Here are some things that the Knowledge Graph might store for “Queen, the band”:
- Freddy Mercury (is a member of) Queen, (which is a) rock band,
- Bohemian Rhapsody (is a) song (written by) Queen, (which is a) rock band
- Innuendo (is an) album (written by) Queen, (which is a) rock band
- Live Aid (is a) concert (featuring) Queen, (which is a) band.
The items in bold are all Entities. They all connect with a relationship (Shown in brackets). That’s really all there is to it! “Person”, “band” and “concert” are really classifications of things. or @types of things, rather than things in their own right… that is to say, many people can be classified as a “person” entity, Queen in this record is classified as a band. In another record, Queen may also exist, classified as (say) a monarch. Some common classifier @types are:
- Person
- Place
- Date
- Organisation
- Review
- Recipe
- Event
By populating the Queen (a band) record with these lines of relationships to other records, the table that is produced acts as a semi-structured dataset about the entity. So when you type in “Queen, band” into Google, not only do you get the official website of the band as you have always done, you also get a “Knowledge Box” which is really just all these relationships laid out in a pretty manner. Their YouTube channel, their Spotify channel, their albums, members and more.
Note the importance of Wikipedia in much of Google’s Knowledge Panel. Google has noted in presentations that it uses the data from the Wikimedia foundation as a primary dataset for training its own systems when building the knowledge graph. IMDB also looks prevalent in this example.
Semantic Triples
A “Triple” in the context of semantic search, is a relationship between two entities or entity @types. (The @ sign that we keep using will start making sense elsewhere in this guide).
If you understand the concept above, you’ll be delighted to understand that “Semantic Triples are even simpler. We used the example: “Freddy Mercury (is a member of) Queen, (which is a) rock band“. This is actually more complicated than a “triple”. In fact, THREE triples are contained in that statement:
- ” Freddy Mercury (is a member of) Queen
- Queen, (is a) rock band
- Therefore we can DEDUCE a third triple that: “Freddy Mercury” (is in a) “Rock band“
Triples make up the core or the knowledge graph. Although interestingly, we see here that incomplete data can create errors. It would be more correct to have said Freddie Mercury WAS in a rock band. Without the date that he died as another triple, the deduction is in fact false. This is because the INPUT data, saying Freddie IS a member of Queen was also false.
How the Knowledge Graph has changed search
Now that Google understands Queen as an ENTITY, Google can then go much further, by enriching the traditional search results, because Google now knows the YouTube channel. So can easily show a few videos in the results, for example.
Notice in the knowledge box for Queen, one of the first entities listed is “queenonline.com”? The official website is in itself an entity related to Queen, the band. It is not surprising, then, that Google also lists that website at the first traditional organic result.
Vectors
Just from that knowledge box for Queen, you can probably see that Google is likely to see that John Deacon and Freddie Mercury are “semantically close” to each other. Similarly, Google thinks the Beatles and Pink Floyd are probably semantically close bands. This is an extremely important concept for SEOs to understand. If you want to write about Queen, the band, then you had better also write about John Deacon and Freddie Mercury. Talk about London in the 1970s and the amazing video techniques used in Bohemian Rhapsody. Of course, this will not help you rank anymore for the term “Queen, band” because that entity is already fully defined and you don’t own the official website (unless you do, in which case, can you please link to this article?). However, you CAN still generate organic traffic relating to Queen, the band. We describe this in the section “optimizing for the edge”.
That didn’t sound TOO scary, I hope. If you want to be a good SEO, though, you’ll need to know more about how machines can take text and convert text into hierarchies and numbers in a way that they can use to provide us, humans, with useful search results.
You can analyze any web page semantically, the way Google does for free at Inlinks.net.
Leave a Reply
Want to join the discussion?Feel free to contribute!