
Summary:
Modern Search Engines can derive insights across multiple documents instantly. Cataloguing systems over the years moved towards “10 blue links” search results and how now moved on to a more encyclopedic format. In a way, the retrieval methods have gone full-circle.
The Journey from Directories to Semantic Search
Back when we all used real-world libraries more (and those libraries are still there, very peaceful places to work now, away from the children’s section), how did the librarian look up where a book was when you asked? She invariably had a cataloguing system. In my youth, this was a card-based system, based on numbers. Today you still see every book in the library with catalogue number stuck to the back.
When the Internet started, Jerry Yang and David Filo thought that someone should start doing the same thing with websites and they formed the YAHOO directory. This was a manually curated list of websites, with a small summary of each site’s purpose and a hierarchical category. By modern standards, it wasn’t sophisticated, but at one point Yahoo was the most valuable online business in the world. Two popular variations of the model were Looksmart, which was used by Microsoft and the Open Directory Project, which was an open-source variation that could be used by any search engine, (later including Google).
Competing with this idea of cataloguing websites was the concept of “full-text search” – which was led by AltaVista and myriad other companies (including a valiant effort by Yahoo) but ultimately won by Google in the west, Baidu in China and Yandex in Russia. Full-text search offered more promise, providing everything could fall into place. Website curation was slow and manual. All the contents of the website had to be explained in a few sentences! Much like a cataloguing system in the local library. Full-text search, on the other hand, needed no manual intervention and every PAGE could be a separate entity in the index. That allowed for a much larger index overall.
Knowledge bases are, to some extent, a swing back to the old way of doing things. We’ll return to this argument later, but first, let’s explore the differences between catalogue or directory-based indexing and text-based indexing and then delve into some of the concepts behind text-based indexing. Time starved SEO experts that already know text-based search may choose to skip to the next section.
Directory-based search vs Text-based Search

There were some advantages of both approaches to indexing the web. There still are. Ultimately the full text-based approach won out until recently. As the web continues to grow, however, Google’s mission of “organizing the world’s information” has hit several new barriers. Given that there are far more pages on the Internet about any given subject than anyone can ever read, how much point is there in Google continually trying to collect the information and order it, if nobody ever looks past the first page of results? Even Google’s resources are finite, and even if they were not, the planet’s resources ARE finite. You may be surprised to learn that one energy website has estimated the power needed to drive Google search is about the same as powering 200,000 homes. Statista reports 4X more energy used by Google, so approaching a million next year if something doesn’t change! Google could still sustain this by buying renewable energy to a point. Even so, Moore’s law, which suggested microchips would continue to get faster and faster has reached both a physical and economic barrier. Quantum computers may fill this void, but right now, any search engine needs to make compromises.
But until this crisis point, the full-text search was killing human-curated search. To achieve quality results for users in full-text search, search engines needed to change text strings (which are notoriously hard for machines to analyse) into numerical and mathematical concepts, which can then be easily ranked or scored, ready for the time when users need answers to their search queries. The process goes something like this:
Crawl and Discover phase
Most search engines discover content by crawling it, although traditional crawling is far from the only way in which search engines can ingest content. According to Incapsula (now Impervia), most web traffic actually comes from bots. This is not just Google and Bing. Distributed crawlers like Majestic (where I used to be a director) a specialist search engine analysing the links BETWEEN web pages, crawls faster than Bing. I discussed this once with a friend in Microsoft and he said that one of Microsoft’s objectives was to reduce the need for crawling altogether. I do not know how true this is, but certainly, at this point, web crawling is the main way in which search engines ingest text. It is also the main way in which they discover new URLs and content to feed these insatiable crawlers because crawling a page reveals links to new pages, which can then be put into a queuing system for the next crawl. Discovery also comes in many other forms. Site maps are very helpful for Google and they make it easy for website owners to submit maps directly into Google through their “Webmaster Search Console”. They can also cut corners by looking at news feeds or RSS feeds which update as the website content updates.
Crawling at scale was relatively efficient for many years. The bot could simply grab the HTML of the page and some other metadata and process the text on the page at a later point. However, technology never stops and first frames, then iFrames, then CSS and then Javascript started to add complexity to this process. Javascript, in particular, creates a huge overhead for search engines to process. Content delivered by Javascript is rendered on the client side. That is to say, your own PC, laptop or phone uses some of its CPU to make the web page appear in the way it does. For a web crawler to read every page on the internet is one thing. For it to crawl it AND understand the Javascript at the same time would slow the crawlers down to such a pace that crawling would not scale. Google, therefore, introduced a fourth step into the process of indexing.
Javascript Challenges
Google currently looks to be leading the charge in analysing Javascript and they have certainly improved significantly over recent years. Nevertheless, the computing overhead required is immense, the processing has to take place sometimes several weeks after the initial crawl and significant compromises have to be made. Martin Splitt, from Google, runs many excellent videos around this challenge.
Turning text into mathematical concepts
Now we turn to the heart of full-text search. SEOs tend to dwell on the indexing part of the search or the retrieval part of the search, called the Search Engine Results Pages (SERPs, for short). I believe they do this because they can see these parts of the search. They can tell if their pages have been crawled, or if they appear. What they tend to ignore is the black box in the middle. The part where a search engine takes all those gazillion words and puts them in an index in a way that allows for instant retrieval. At the same time, they are able to blend text results with videos, images and other types of data in a process known as “Universal Search”. This is the heart of the matter and whilst this book will not attempt to cover all of this complex subject, we will go into a number of the algorithms that search engines use. I hope these explanations of sometimes complex, but mostly iterative algorithms appeal to the marketer inside you and do not challenge your maths skills too much.
If you would like to take these ideas in video form, I highly recommend a video by Peter Norvig from Google in 2011: https://www.youtube.com/watch?v=yvDCzhbjYWs
Continuous Bag of Words (COBW) and nGrams
This is a great algorithm to start with because it is easy to visualize. Imagine a computer reading words at breakneck speed. It reads a word on a page, then the next, then the next. Every word it reads initially makes a decision:
Decision: Is this word potentially important?
It makes a determination here by stripping out all those very common words like “an”, “it”, “as”. It does this by checking against a (curated) list of STOP words.
Decision: is this the right variant?
At the same time as deciding whether to drop a word, it might change the word slightly, by removing the “s” from “horseshoes” or matching capitalized words with non-capitalized variants. In short, it aggregates different variants into one form. We’ll return to this when we talk about entities because there’s not much difference between “litter”, “rubbish” and “garbage”.
Then the system simply counts words. Every time it sees the word “Horseshoe” it adds 1 to the total number of times it has seen the word horseshoe on the Internet and adds 1 to the number of times it sees it on the page it is currently looking at. Technically, Information retrieval experts call pages “documents”, mostly due to historical reasons before the Internet was a thing, but possibly in part just to make us mortals feel inferior!
Now, the search engine can easily see that a searcher looks for the word “horseshoe” it can find the page with the word most densely mentioned on it. This is a pretty BAD way to build a search engine because a page that just spams the word horseshoe would come to the top, instead of one that talks about horseshoes, but we will come to dealing with this kind of spam when we talk about PageRank and other ranking tools. It is a GREAT way, however, of storing all the words on the Internet efficiently. Whether the word is used once or a million times, the amount of storage needed is about the same and only increases by the number of pages on the Internet. (Information retrieval experts partly call the Internet the “corpus” of “documents” here… partly due to historical reasons, but now I am beginning to think they do it through some sense of passive-aggressive intellectualism. You judge for yourselves.)
This system gets much more useful when the crawler starts counting words that are next to each other, called n-grams. The crawler can then count the number for phrases several words long, after first stripping out the stop words and choosing the dominant variant of each word. Google even went so far in 2006 to publish a data set of n-grams for 13 million words, which is shown in Peter Norvig’s lecture and remains available for download.
- Number of sentences: 95,119,665,584
- Number of unigrams: 13,588,391
- Number of bigrams: 314,843,401
- Number of trigrams: 977,069,902
- Number of fourgrams: 1,313,818,354
- Number of fivegrams: 1,176,470,663
Now we can glean huge amounts of information from this information. Google knows that the phrase “the quick fox” is much more common than “the clever fox” on the internet. It doesn’t know why, but it does not need to. It only needs to return relevant pages for “the quick fox” when a person searches for this. If you are not sure why a fox is more likely to be “quick” than “clever”, it is because this forms part of a famous sentence that uses all the letters of the alphabet, making it ideal for teaching people to type on a QWERTY keyboard.
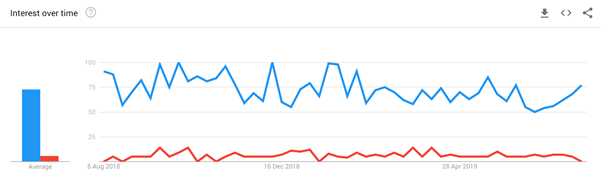
Figure 1: You can also check search usage. Blue is “the quick fox” while red is “the clever fox”
A search engine can look at the number of times the words in the search – both individually and as a group – appear on a page. Spamming aside, there are myriad ways to then score each document for this phrase. A search engine is born!
Vectors
There is another revelation here. Having seen that “the quick fox” is much more popular as a phrase on the Internet than “the clever fox”, we can also deduce that the word “quick” is semantically closer to the word “fox” than “clever”. There are many algorithms, such as “Word2Vec” that use this kind of intuition to map words based on their “proximity”. “King and Queen” end up close, whilst “king and fox” end up very far apart. For further reading on this, look up “Vector Space Models“.
The move to Semantic Markup
By adding Semantic Markup to pages, Google and other search engines can shortcut the algorithms that they need to turn words into concepts. You help explain the content in a way that machines can digest and read. However, on its own, it would be very easy for web content to abuse this system. The knowledge graph needs to only augment the information that it already has when it is confident that the recommendations in the semantic markup are valid. If the search engines get this wrong, then Semantic Markup would be a little more effective than the “olden days of SEO” with keyword stuffing.
To do this, Search engines still need to trust humans! The Knowledge Graph started with a human-curated set of data.
Trusted Seed Sets: A glorified directory!
We started the journey of search by discussing how human-led web directories like Yahoo Directory and the Open Directory Project was surpassed by full-text search. The move to Semantic search, though, is a blending of the two ideas. At its heart, Google’s Knowledge-based extrapolates ideas from web pages and augments its database. However, the initial data set is trained by using “trusted seed sets”. the most visible of these is the Wikipedia foundation. Wikipedia is curated by humans and if something is listed in Wikipedia, it is almost always listed as an entity in Google’s Knowledge Graph.
This means that the whole integrity of the Entity based approach to search depends on the integrity and authenticity of those (usually unpaid) volunteers curating Wikipedia content. This produces challenges of both scale and ethics which, which are discussed by the author here.
So in many regards. the Knowledge Graph is the old web Directory going full circle. The original directories used a tree-like structure to give the directory and ontology, whilst the Knowledge Graph is more fluid in its ontology. In addition, the smallest unit of a directory structure was really a web page (or more often a website) whilst the smallest unit of a knowledge graph is an entity that can appear in many pages, but both ideas do in fact stem from humans making the initial decisions.
This leads us on to what Goggle considers an entity and what it doesn’t. Clearly, knowing this is important if we are to start “optimising” Semantic SEO.